

Versioning
Applying the FAIR principles onto a dataset requires ticking numerous different checkmarks. For many experimental life-cycles, this FAIRification process is triggered when publication of the research draws near. But this comes with a plethora of potential problems. Most importantly, these publications can only provide a single, immutable snapshot of the research.
#Immutable yet evolving
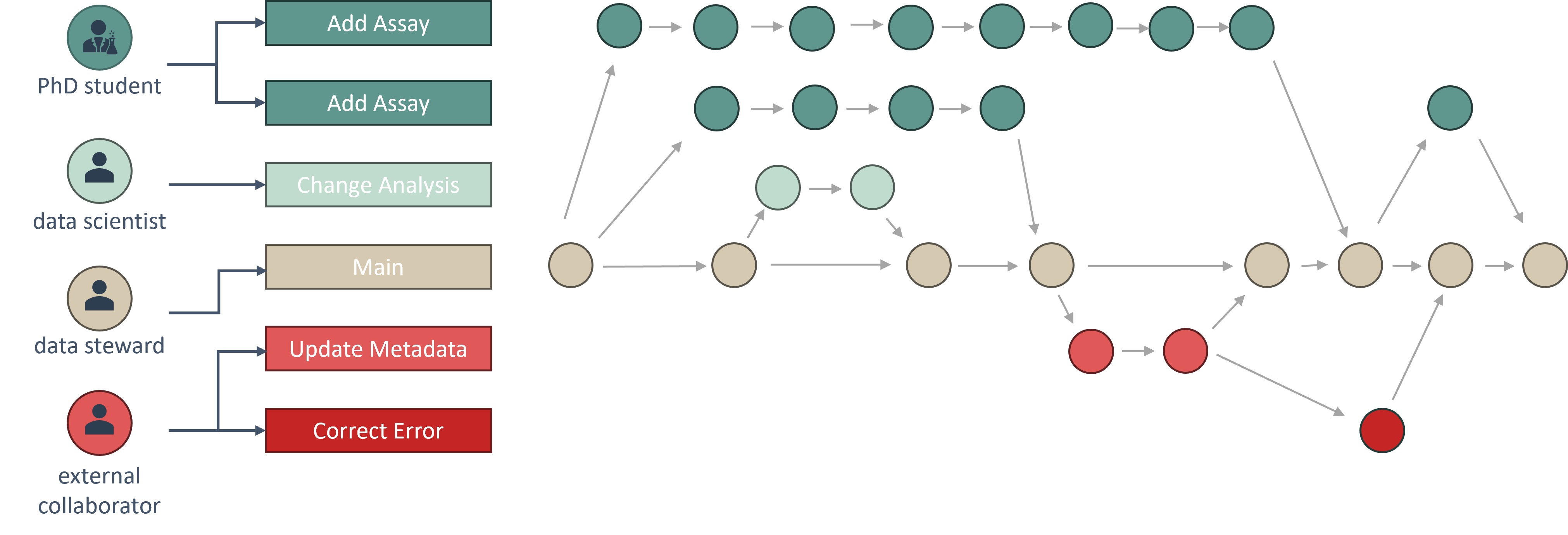
In reality, research is a continuous process both preceding and succeeding the publication, i.e. an evolving sequence of snapshots, including intermediate or negative results. Therefore, a method is needed to allow applying the FAIR principles incrementally, accompanying the whole research cycle. For this, ARCs inherit a well established concept from Software Development for making the process of collection, annotation, and analysis of data more dynamic, namely versioning. For this, all ARCs are also Git repositories.
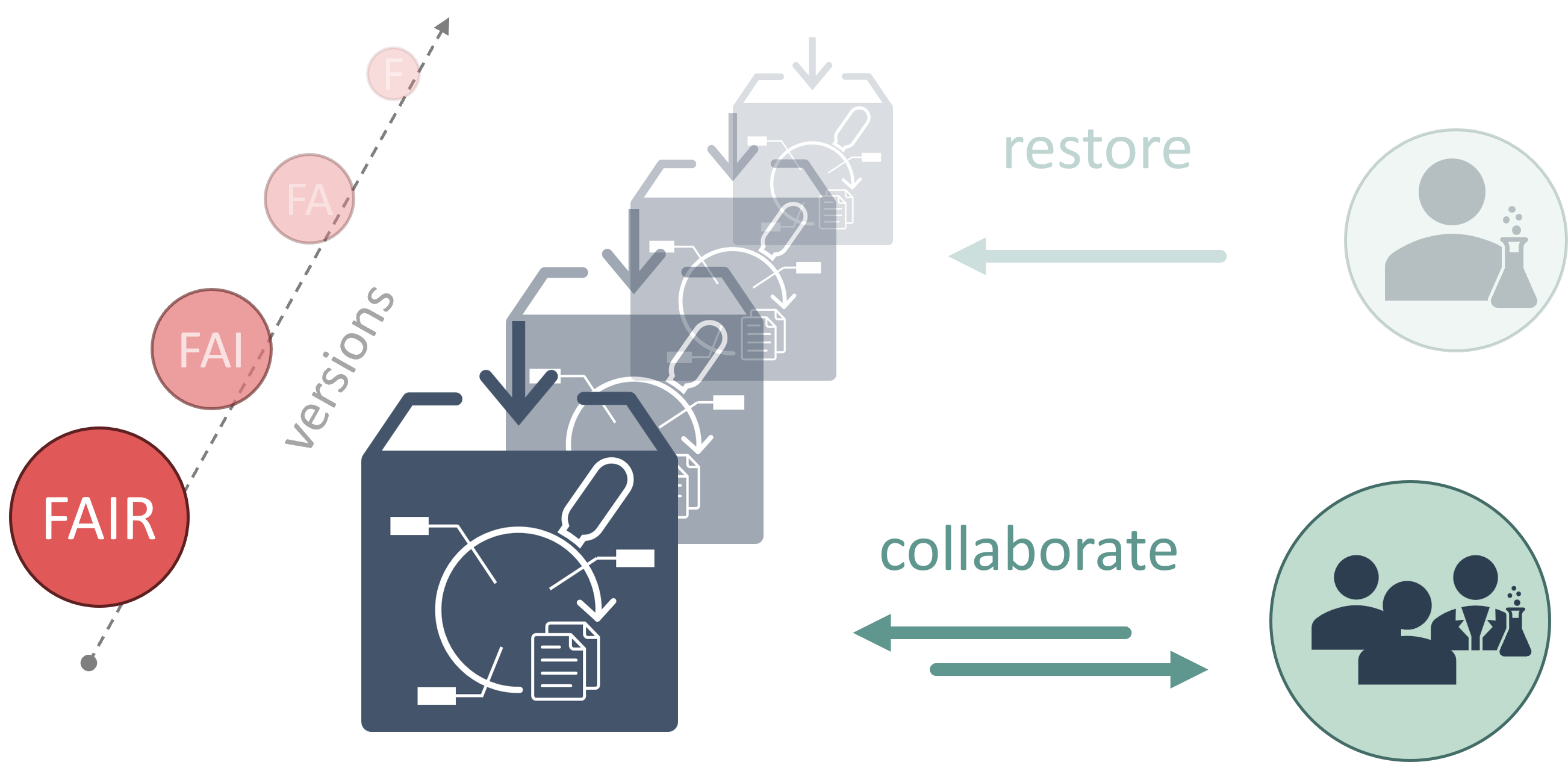
Using Git allows for the ARC to grow together with the experiment, possibly even across multiple publications. Besides this, ARCs can be shared across any Git -based platform. With Git being this wide-spread, there exist numerous hosting solutions, both publicly available and on-premise.
As research is becoming increasingly multi-disciplinary, collaboration is usually given. This collaboration should also extend to the process of fostering the ARC, as most information about an area of research can be provided by the expert conducting it. Git has well-established capabilities and workflows to allow both parallel and sequential collaboration, ensuring sanity of information and provenance of the contributor.
Data is an integral part of ARCs and data size can vary vastly across different scientific domains. In order to handle large files, which can be challenging, Git LFS is used in ARCs. By this extension, the standard Git operations can be used as usual, with additional LFS capabilities being available.