

Documentation and Annotation
#Documentation Principle
In the course of addressing individual research questions, researchers generate data through systematic investigations. These investigations involve a structured process aimed at exploring and examining specific questions or problems to uncover new insights or evidence. The Annotated Research Context (ARC) serves as both the documentation framework and the container that organizes the investigation, encompassing all collected data, metadata, and analyses. While the ARC covers the entire research cycle, this document focuses on annotating and structuring the preparation of experiments, the process of data collection, and its analysis.
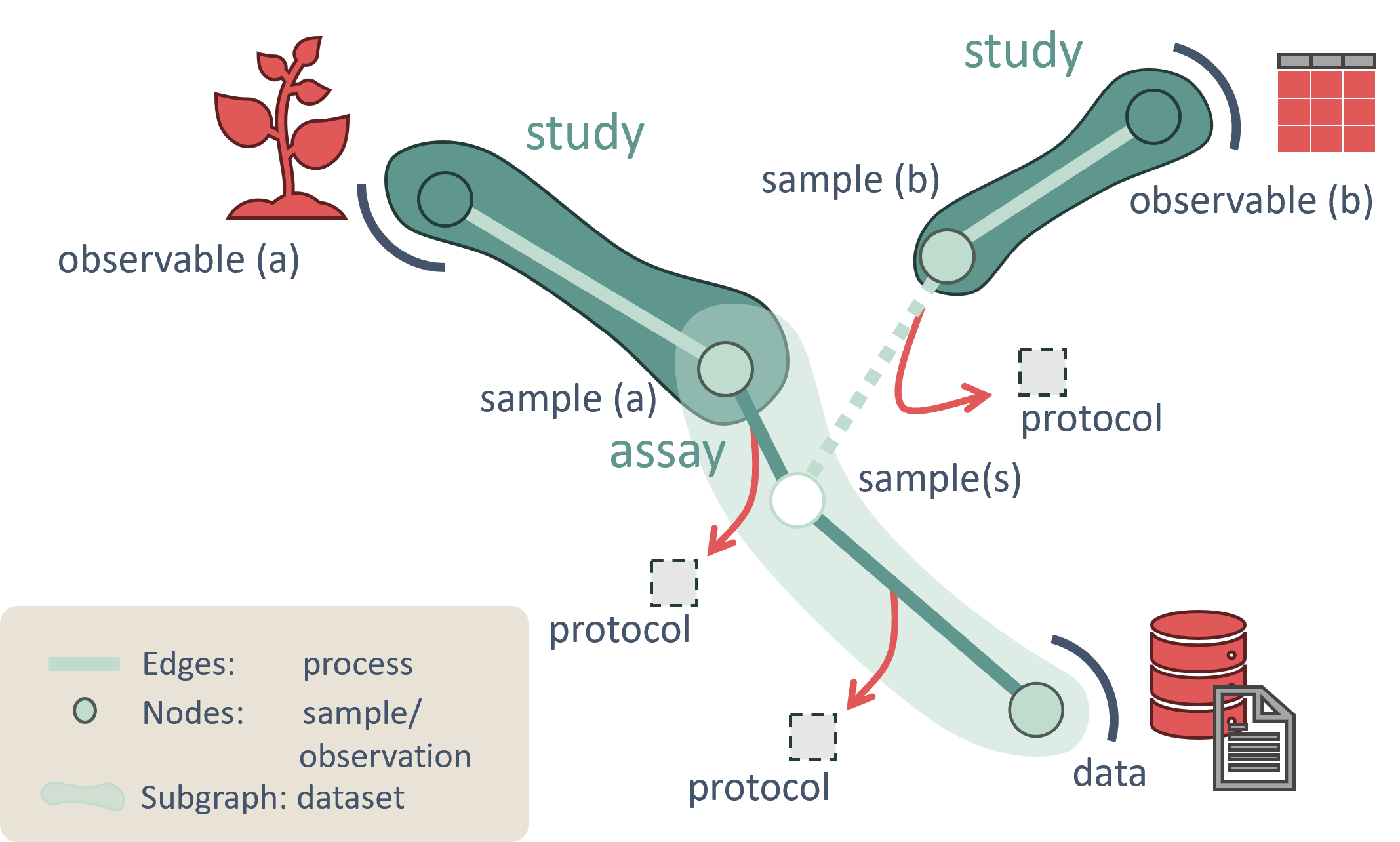
To facilitate a shared understanding, a standardized nomenclature is introduced. The ARC adopts and extends the widely used ISA model, where ISA stands for Investigation, Study, and Assay. In addition to the ISA framework, the ARC includes Workflows and Runs.
A single ARC encapsulates one investigation. The metadata of an investigation includes a title and a description of its focus. The authors and contributors to the research may include colleagues, measurement facility experts, bioinformaticians, supervisors, and supporting technicians.
Crucially, the investigation also holds information about the objects or samples under study, which may be grouped into one or more studies. The study metadata describe the samples and observables, especially the processes leading to sample generation. One or more studies may be included in an investigation, depending on how the samples are intended to be processed or analyzed.
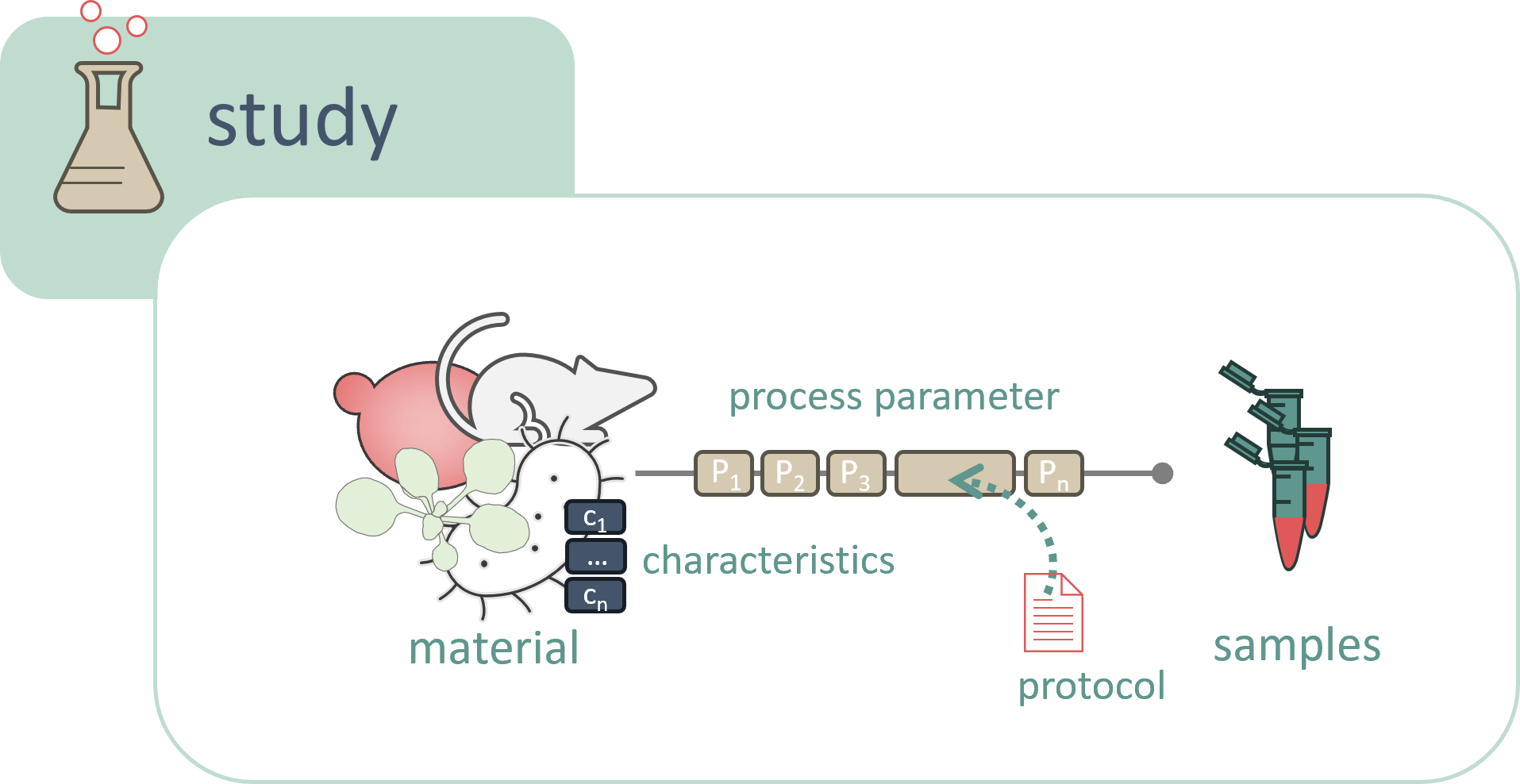
Samples, once created, typically undergo assays, which involve measurements or analyses of samples from one or multiple studies. The assay includes both the data generated and the metadata describing the process. If the samples require special treatment for a specific assay, the relevant metadata should be incorporated into the assay documentation.
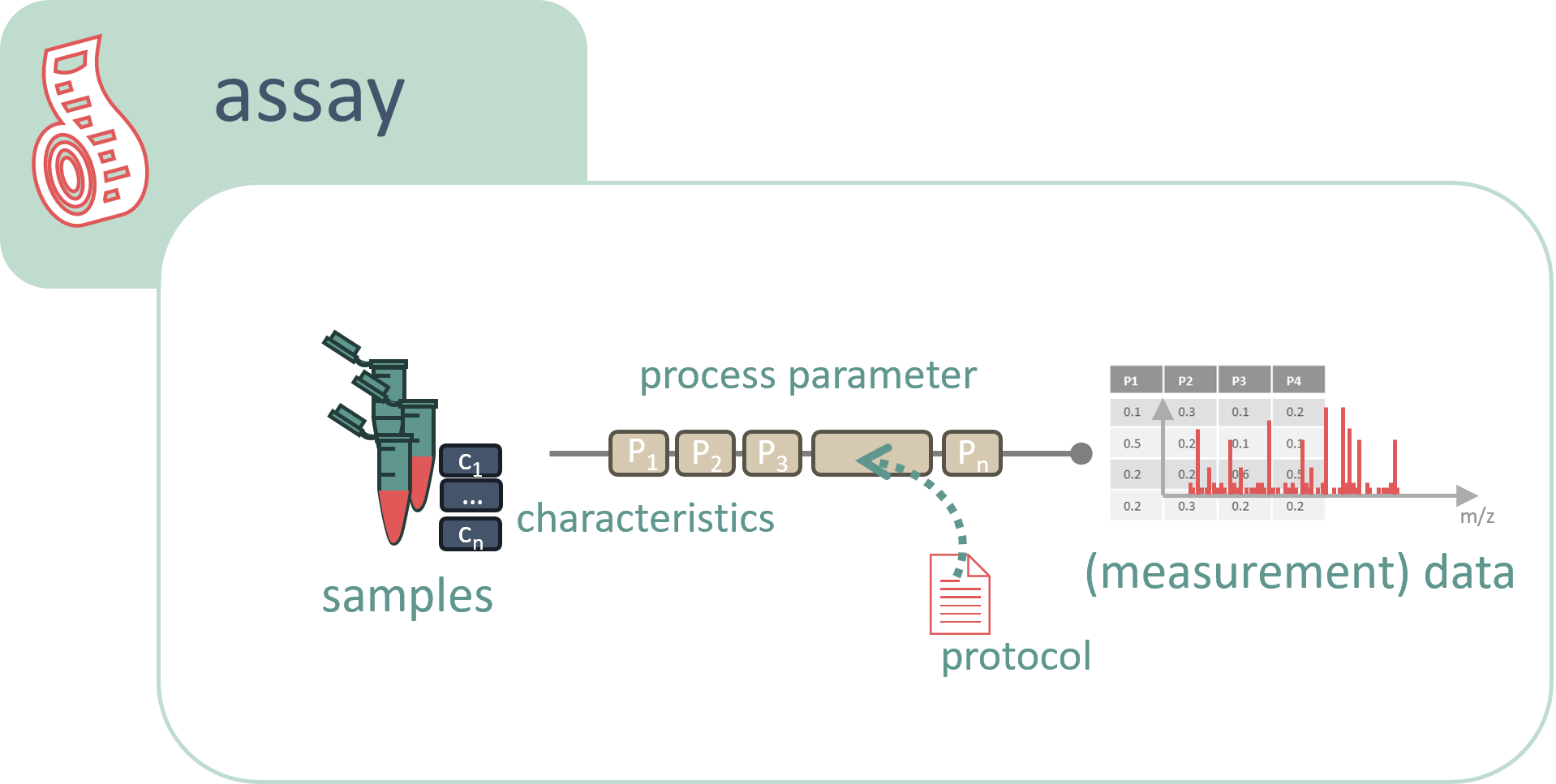
When computational analysis is performed on a sample or on the data resulting from an assay, this process is referred to as a run.
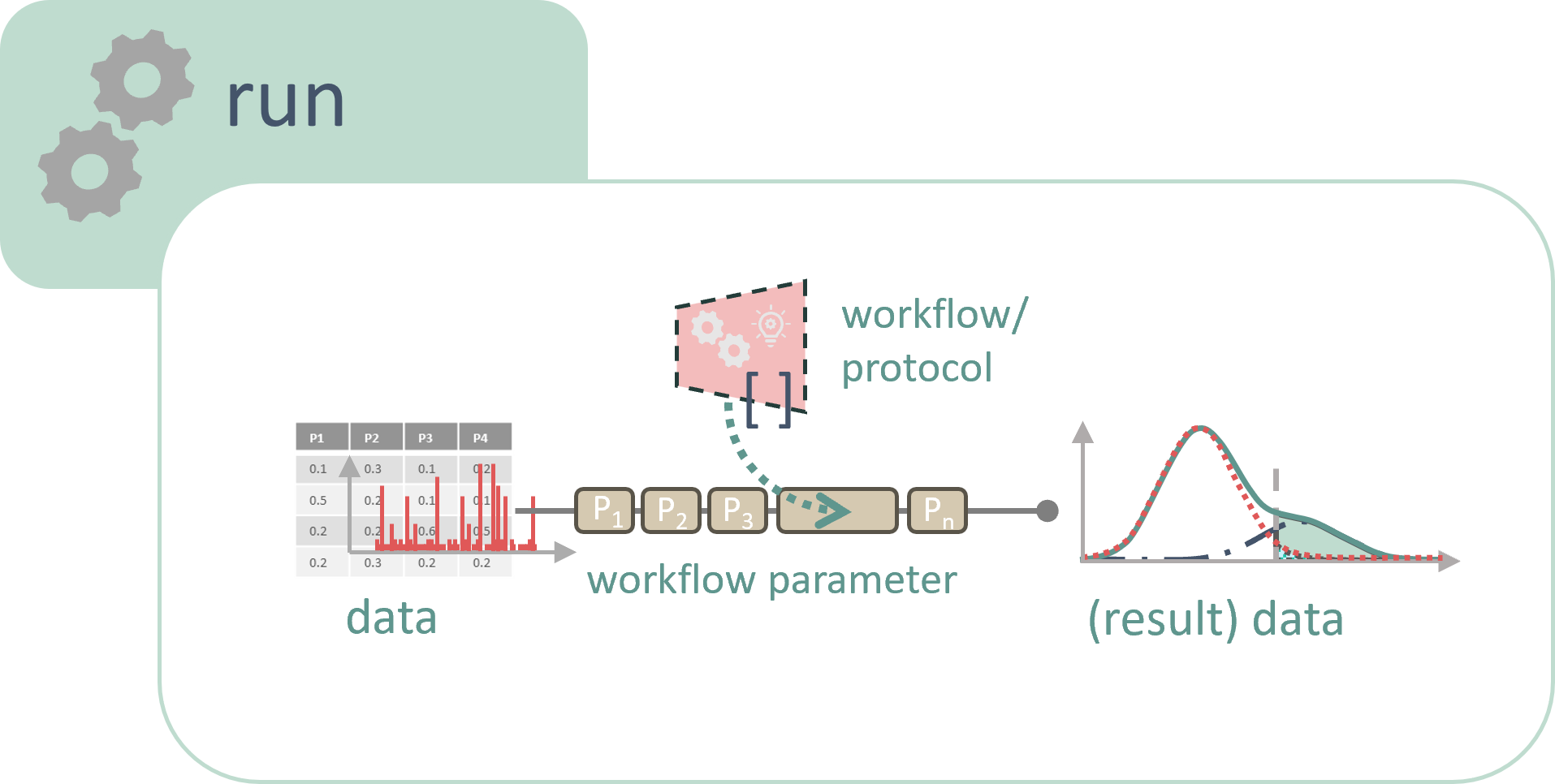
A workflow, on the other hand, is the computational protocol detailing how the data is processed, simulated, or analyzed on a computer without actually executing the computation. Since workflows offer significant value for reuse in other datasets, they are documented separately from runs.
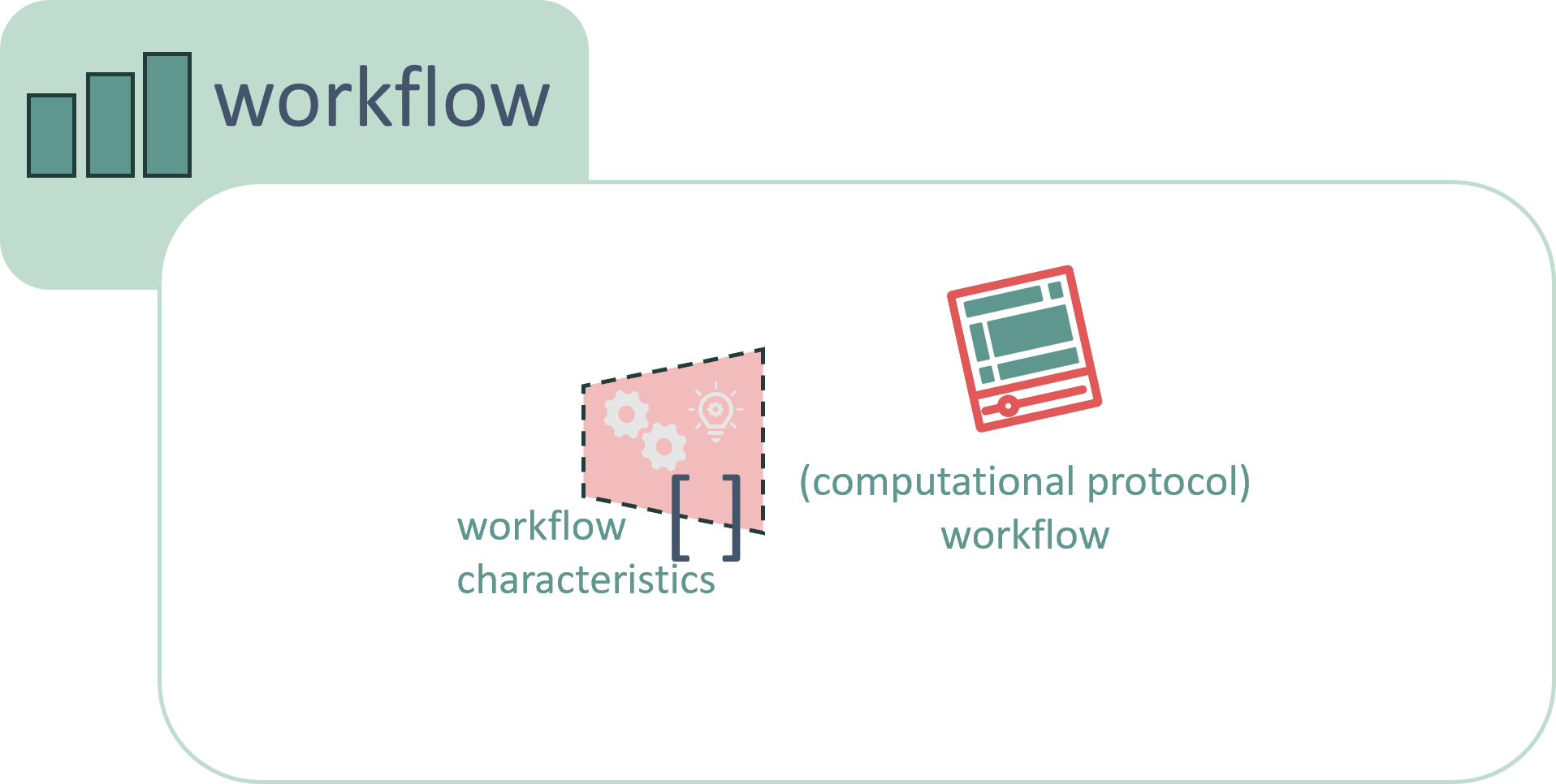
(The term “experiment” is avoided here to prevent confusion, as it can intuitively overlap with “investigation,” “study,” or “assay” depending on context.)
#Annotation Principle
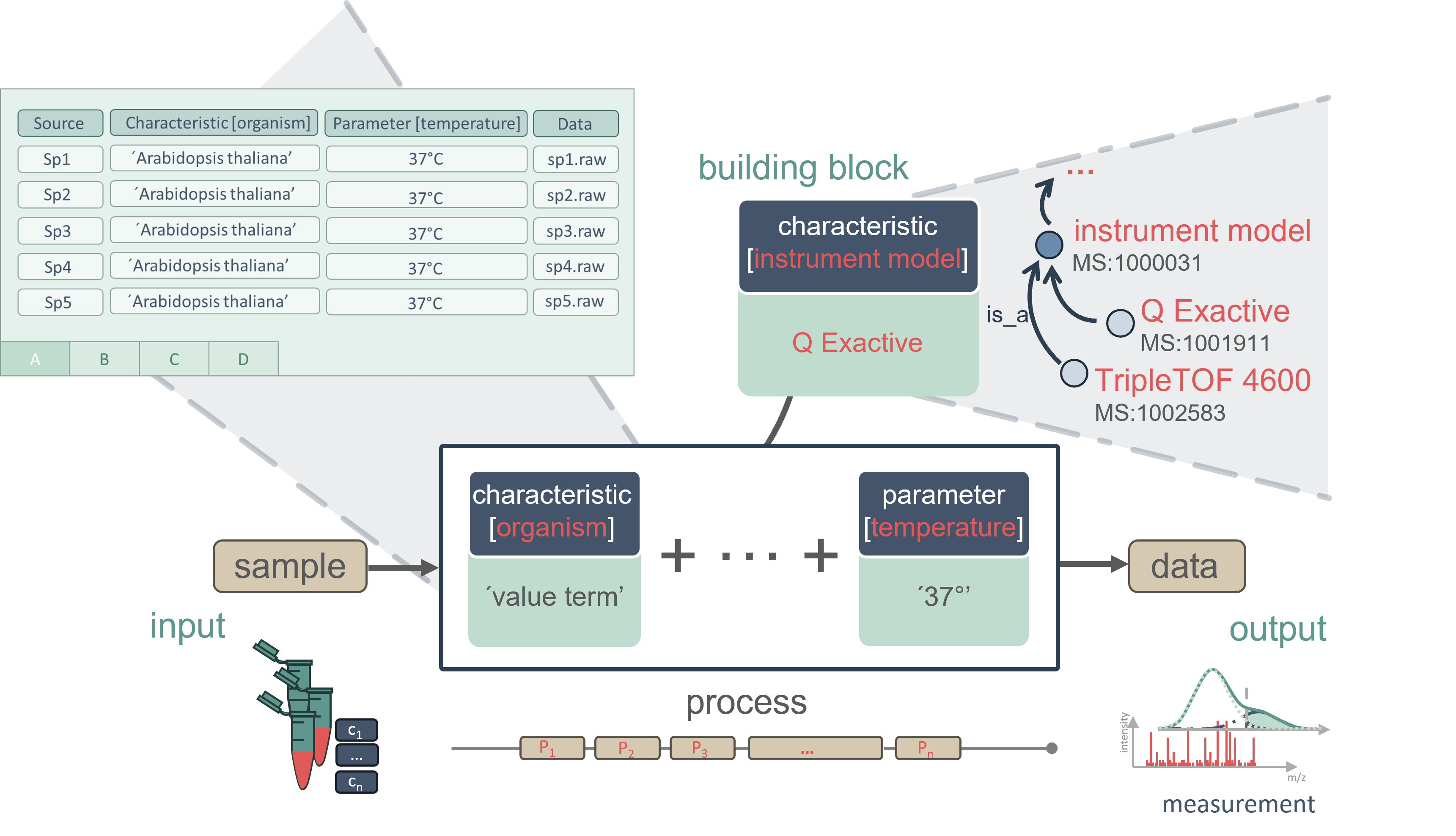
The ARC annotation principle aims to document all processes—from the object of study, through measurements and analysis, to the final results—as data. Each step, whether it involves sampling, sample preparation, measurement, simulation, or analysis, is treated as a process that generates outputs. These outputs can take the form of result files or sample identifiers, which in turn serve as inputs for subsequent processes. This allows for the chaining and branching of different processes, effectively modeling real-world workflows in the lab and providing a clear, documented path leading to the final results.
Each process is annotated with descriptive metadata in the form of key-value pairs, where the key defines the type of data, and the value may optionally include a unit. For example, the key might be “temperature” with a value of “37” and a unit of “°C.” To maintain consistency, avoid errors, and support FAIR data principles, keys should be selected from domain-specific terminologies or dictionaries, where each term or its ID can be referenced. If the value is not numerical, it is recommended to use a controlled term from such a dictionary.
In the ARC, metadata is organized in tables. The headers store the keys (tags), while the corresponding values are recorded in the cells below. Each row represents a complete path from input to output, detailing the processes or steps involved in producing a given output from its initial input.
Special header keys have specific meanings, such as sample name, protocol reference, and data.
#ISA Model Key Parametrization
Following the ISA model, parametrization keys are enclosed in square brackets. An additional column type is written before this key to specify what the content in the column is referring to. Common types include:
- Parameter: Typically used for process-related metadata.
- Component: Refers to an element used during the process.
- Characteristic: Describes the properties or characteristics of the input to a given process.
The main column is followed up by additional columns providing contextual information about the ontology terms used.
#ISA Input/Output Typization
To annotate the entities that are transformed and created in the processes, Input and Output columns are used. The type of entity is enclosed in square brackets. Common types include:
- Material: Physically existing entities.
- Sample: Physically existing biological samples.
- Data: Digital data stored in the ARC or online.
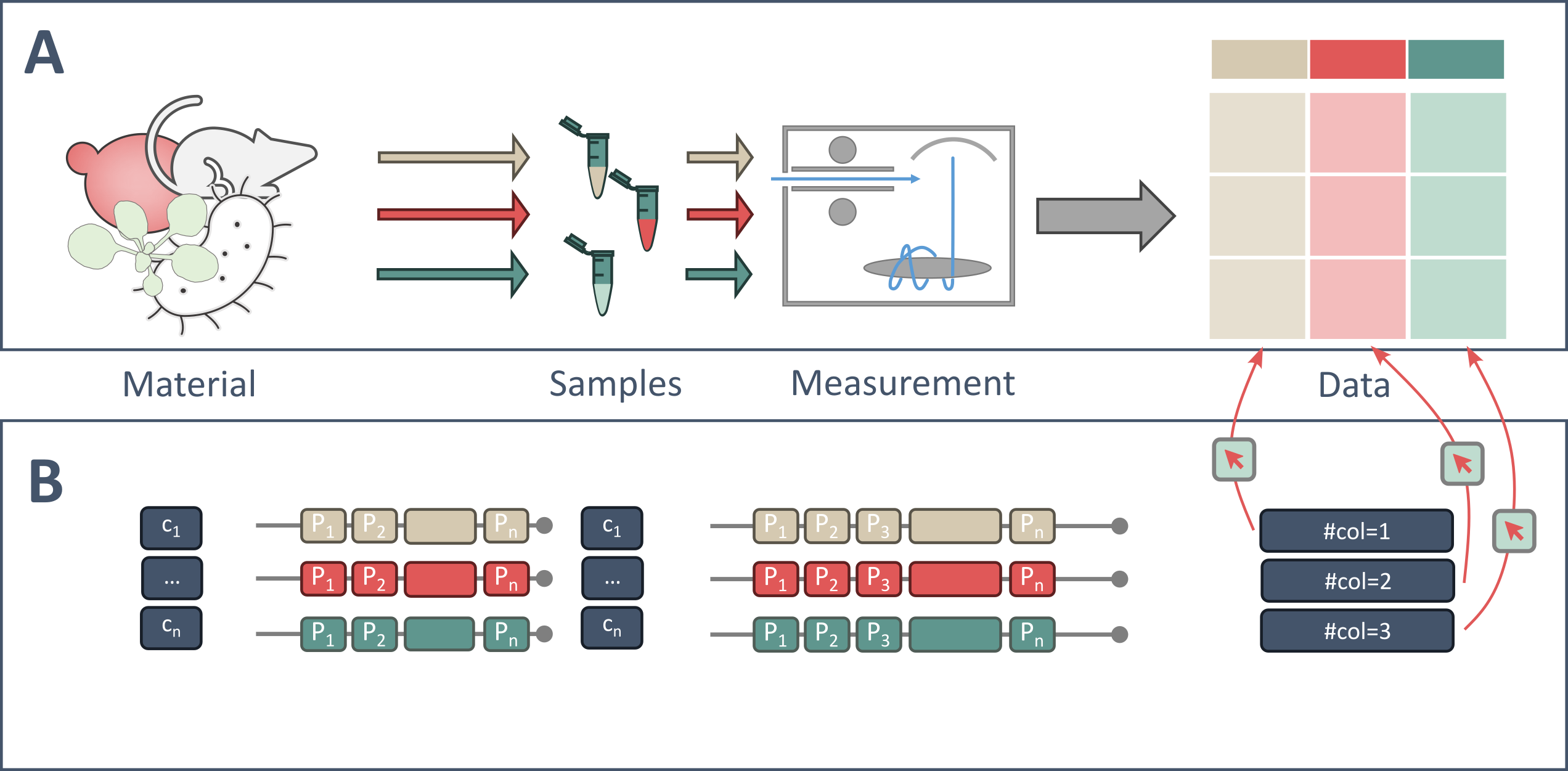
Different entities of data, stemming from distinct process setups or parallel measurements of distinct input samples, are often stored together in the same data file. In these cases, referencing the data file does not unambiguously represent the provenance graph. Therefore, following well established semantic web standards, Data Fragment Selectors can be appended to the file path to annotate specific fragments of these files.
Data-Fragment annotation
#Data Fragment Annotation
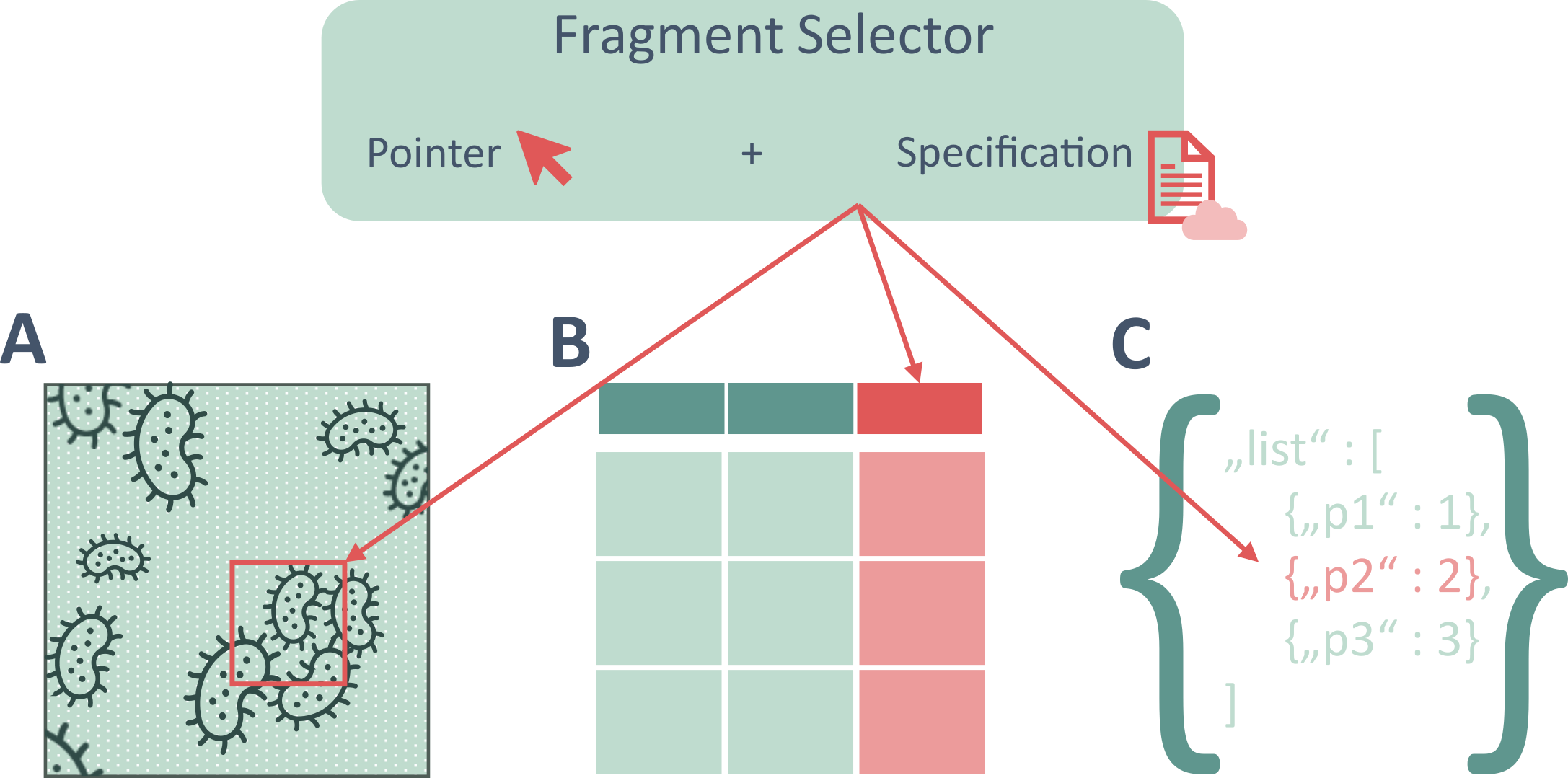
When a single data file aggregates measurements from different samples, conditions, or steps, pointing only to the file path is too coarse to reconstruct provenance. To make such files unambiguous and reusable, ARC supports Data Fragment Selectors (DFS): compact, file-format–aware pointers that reference precise regions within a file.
Data Fragments consist of two parts: a segment identifier (or pointer), which is a simple text representing a specific portion of a file, and a specification URL, which describes how to interpret this identifier. Through keeping this specification variable, Data Fragment Selectors can be used to basically point to any kind of segment in any kind of file. E.g.: col=5 (a column in a table), xywh=100,200,50,50 (a rectangular region in an image) or t=5-15 (a time slice in a signal).
Practically, a selector is appended to the file’s URI as a fragment (after #), such as results.tsv#cell=col=5. The accompanying fragment identification specification in this case would be RFC71111. In the web-world, many Data Fragment Selectors already enjoy frequent usage. For example, you can access this section of this page following the full URL https://arc-rdm.org/details/documentation-principle#data-fragment-annotation.
By encoding all information needed to both understand the data file structure and find the data file segment in question, we can look at data file structure and metadata annotation separately. The two can evolve independently: you can reorganize a file (e.g., reorder columns) and update the selector without rewriting your scientific description, or refine the description (e.g., add an ontology term or unit) without touching the file. This simple separation is what enables fragment-level FAIRness in ARC: machine-actionable, precise, and portable annotations that scale from whole files down to individual cells.
#Datamap
A Datamap is the lightweight container that carries those fragment-level annotations. Conceptually, it is a collection of Data Contexts, where each Data Context binds one Data Fragment to additional metadata: what the fragment represents (e.g., “glucose concentration”) and how to interpret values (units, datatype). Each Data Context is a small, explicit annotation of a singular data entity, enriched through the use of ontologies. A Datamap therefore lets software parse heterogeneous files reliably and validate values against controlled vocabularies.
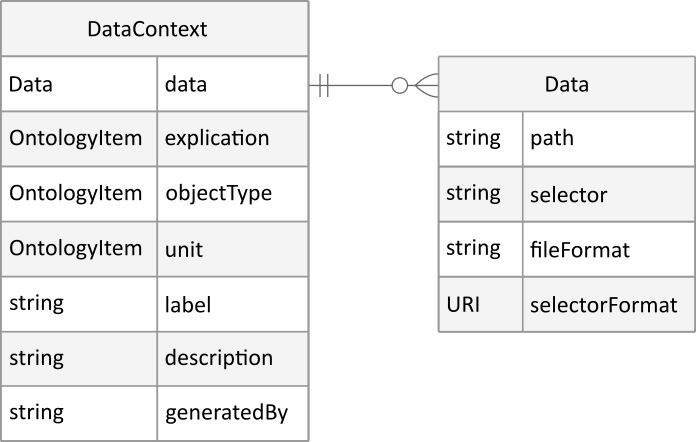
In ARC, the Datamap is intentionally file-format agnostic and exchangeable. It can be authored as a tabular sheet with fixed columns ( ISA -XLSX style), where each row is a Data Context for one fragment, and it can be serialized as a JSON-LD view inside the ARC’s RO-Crate representation. These two serializations are different views on the same abstract model and map one-to-one.

The Datamap holds an important spot in the ARCs annotation principle. It allows to statically schematize and annotate data entities, often orthogonally to the provenance annotation. By co-locating the Datamap and dataset within your ARC, you keep the dataset’s internal structure transparent, bind it to shared vocabularies, and make fragment-level provenance and reuse straightforward for both humans and machines.
These conventions ensure a structured and consistent approach to annotating complex experimental workflows, making the data more traceable and understandable.