

ARC Validation
Due to the immutable yet evolving nature of an ARC, completeness of information can be achieved gradually without creating roadblocks during the process of data annotation. This means that the annotation process is designed to never fail, even if it is incomplete, allowing for continuous improvement and refinement.
To ensure the quality and integrity of an ARC throughout its lifecycle, a mechanism for continuously assessing quality metrics is indispensable. This supports the ARC’s role as the foundation for a data peer-review process, similar to traditional journal publications, but with strong digital validation assistance.
The term validation is often used across different fields with varying interpretations depending on context. In data validation, this generally refers to two main aspects: syntactic and semantic validation. Additionally, although not within the scope of this article, Continuous Quality Control (CQC) processes can be performed using ARC’s validation framework through unit testing and extended to programmatically execute QC workflows, presenting respective results.
#Syntactic Validation
Syntactic validation refers to the structure or format of data. For example, ensuring that a JSON or XML file is correctly formatted so that a parser can read it fully and without errors.
In the context of ARCs, it is important that syntactic validation does not block the user’s workflow. Instead, it should notify the user of issues while allowing them to continue working, preserving the ARC’s philosophy of an immutable yet evolving system.
#Semantic Validation
Semantics deals with meaning. In terms of data validation, it ensures that data is not only correctly structured but also meaningful and usable in a given context. This could mean ensuring that the data adheres to expected ranges or that it is interpretable by consuming applications. For example, in a JSON file, JSON Schema can be used to define specific requirements for semantic validation, ensuring the data is relevant and usable within the context of an application.
Most real-world data validation scenarios rely on semantic validation following an initial syntactic check, as the context in which the data is used is critical for determining whether it is meaningful and actionable.
#How to validate ARCs
#1. Virtually All File Formats Are Allowed
ARC’s broad specification means that it supports a wide variety of file formats, making holistic syntactic validation infeasible. However, the metadata documents within the ARC representations (e.g., ARC RO-Crate or ARC Scaffold) can still be syntactically validated.
#2. No Single Domain Context
Since the ARC is designed to accommodate data from any domain, it does not enforce a single semantic validation framework. Each ARC may contain data from different types of experiments or workflows, which means that target-specific semantic validation is the only feasible approach. There is no universal domain logic to apply across all ARCs.
#3. External or Generative References
The ARC is not a single document but a collection of files, data, workflows, and results, which may reference external data sources or ontologies. For instance, a file path might be correctly formatted, but the referenced workflow may need to be executed to verify its validity. Therefore, validation must be able to account for dynamic and external references.
#4. Unit Testing as a Solution
To address these challenges, principles from software development — specifically unit testing — can be applied. In unit testing, a set of fine-grained assertions or requirements is defined, which the system must satisfy. Similarly, ARC validation can be handled through context-specific assertions based on the type of experiment, methodology, or repository being used. This may involve external data retrieval, program execution, or conditional validation, depending on the context.
#Validation via a Pull Model
Given the complex, multi-modal nature of ARCs—which may contain data from various scientific assays, measurements, simulations, and workflows, a one-size-fits-all validation process is not practical. Instead, ARC validation is implemented using a pull model, where only the relevant parts of the ARC needed for specific validation assertions are retrieved and validated.
This targeted approach minimizes unnecessary workloads for researchers. For example, shared sample information across multiple assays or overlapping (meta)data can be reused. This ensures that validation efforts are focused on the context-relevant aspects of the ARC, rather than unrelated (meta)data.
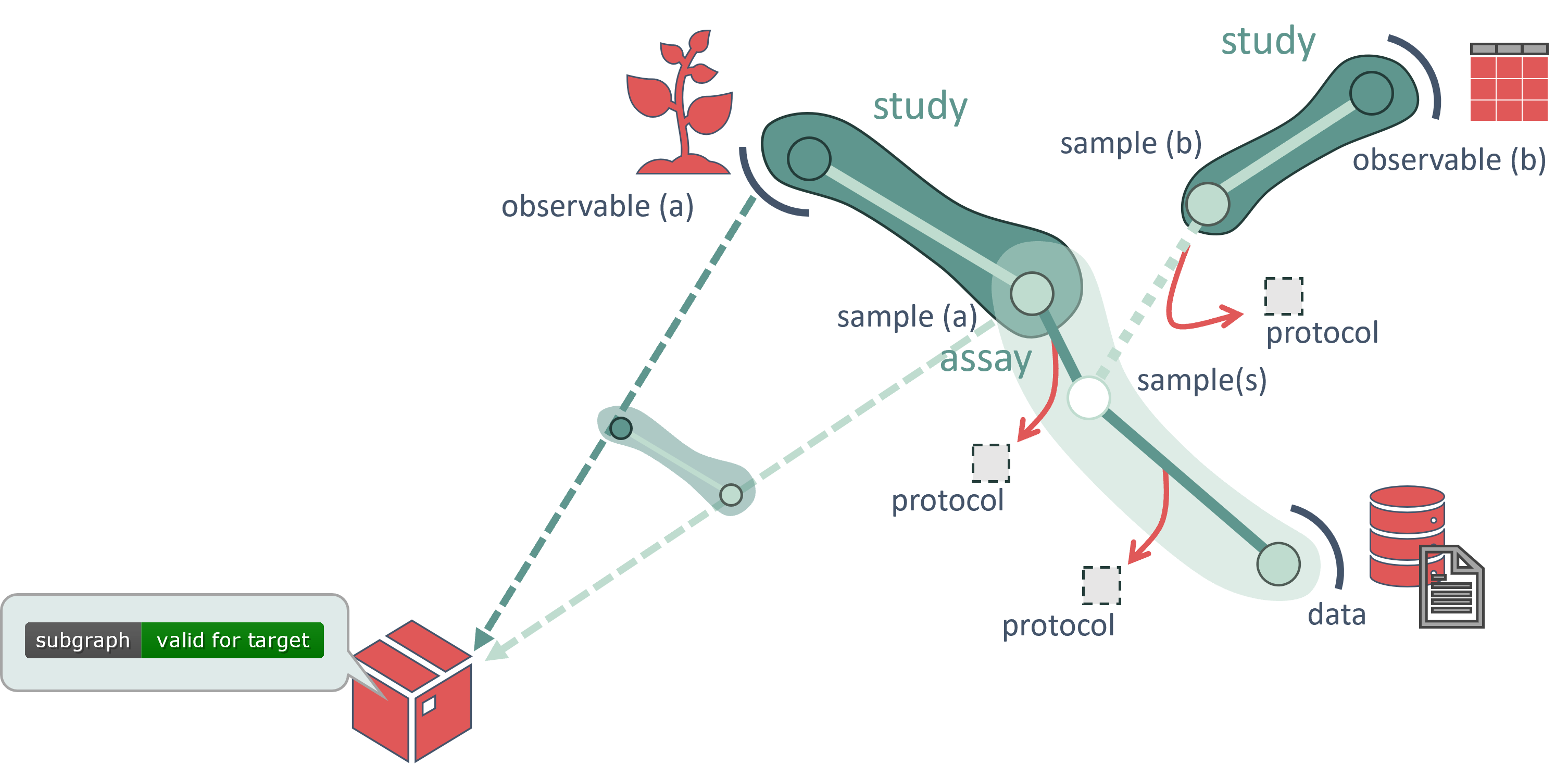
In this model, a validation package pulls the necessary context from the ARC for its specific assertions. This enables a customizable validation process, allowing researchers to maintain high (meta)data quality according to individual requirements, without compromising flexibility. As a result, the ARC can continuously evolve and improve throughout its lifecycle.
#ARC Validation Package Ecosystem
The ARC’s validation framework extends beyond simple checks to ensure the compatibility and integrity of partial ARCs, such as individual assays. Connecting, linking, or transferring parts of an ARC to technology-specific endpoint repositories or domain-specific databases is supported. Researchers can also customize validation to meet specific project, lab, or institutional requirements, automating these processes with ease.
By building the validation process on unit testing principles, ARC validation can be executed using any programming language that supports unit testing frameworks, fostering an open and adaptable ecosystem. Unit testing ensures that validation results are presented consistently, often as user-friendly design elements like badges, regardless of the implementation behind the validation.
Moreover, ARC offers an ecosystem of validation packages designed to address the target-specific nature of ARC validation. These packages define sets of assertions tailored to particular validation needs. Validation packages can be shared, modified, and improved incrementally, much like software libraries. Central registries help manage and distribute these packages, ensuring that the validation process remains transparent, accessible, and easily reusable across different research contexts.
By adopting this flexible, modular approach, ARC empowers researchers to automate (meta)data quality control, ensure (meta)data integrity, and continuously adapt to evolving scientific needs, all while maintaining an open, collaborative framework for data validation.